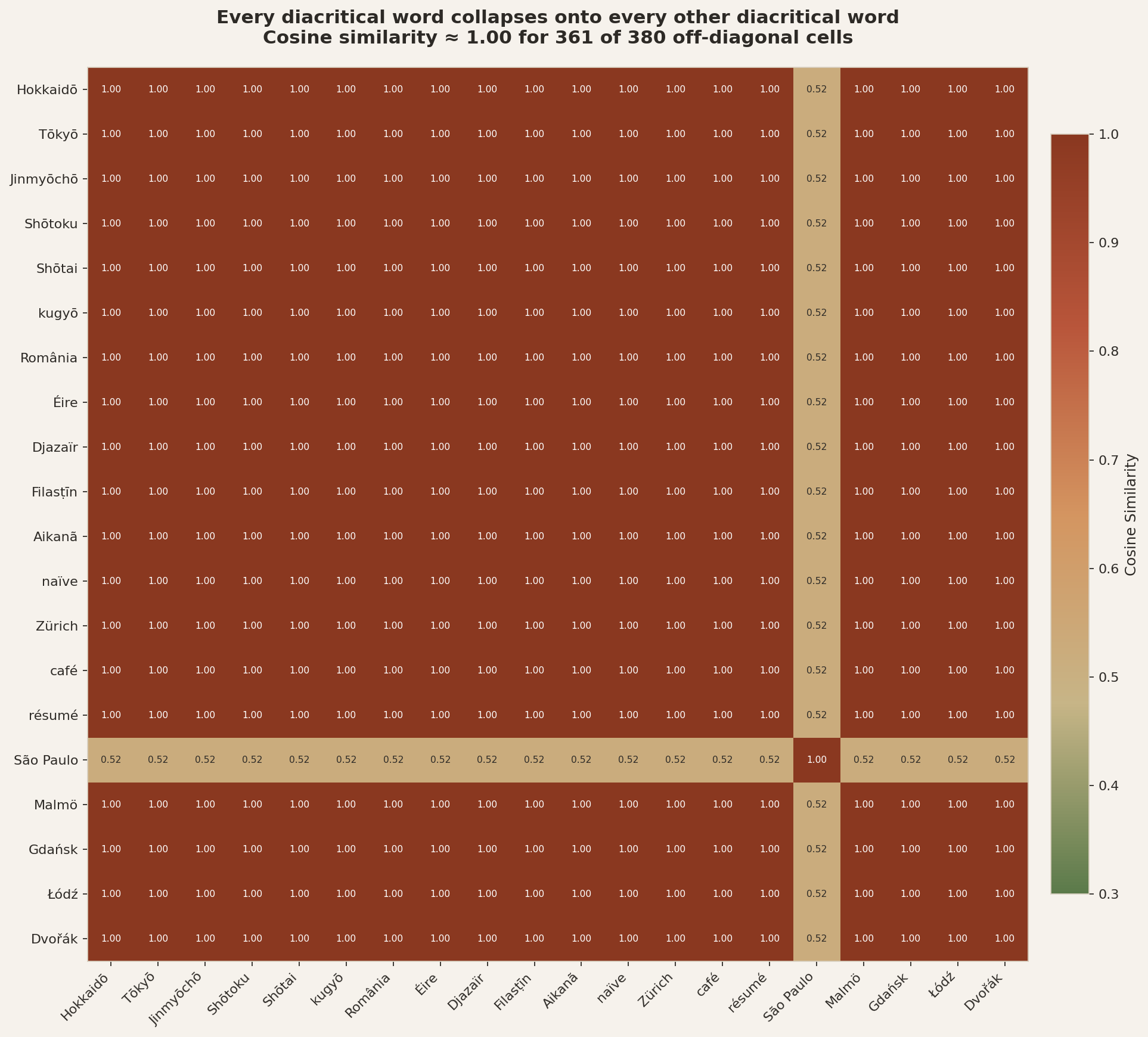
Figure 1: 361 of 380 off-diagonal cells are at cosine ≈ 1.00.
A top-ranked MTEB embedding model collapses nearly every word containing a
diacritical mark to a single point in vector space — but only when
deployed via Ollama. The upstream HuggingFace tokenizer strips accents
correctly; the Ollama gguf conversion pipeline silently drops the
preprocessing step, and the defect class affects every BERT-derived
embedding model in the local-inference stack we tested.
147,687 confirmed cross-entity collisions on Wikidata.
Last updated: 2026-04-11 23:43 UTC
· regenerated from
scripts/verify_tokenizer_divergence.py
mxbai-embed-large is a top-ranked open-source embedding model on MTEB.
When deployed via Ollama — the dominant local-inference stack for
embedding models — it has a silent tokenizer defect that collapses any short text
containing diacritical marks (ō, é, ü, ł, ṣ, …)
into a single point in embedding space.
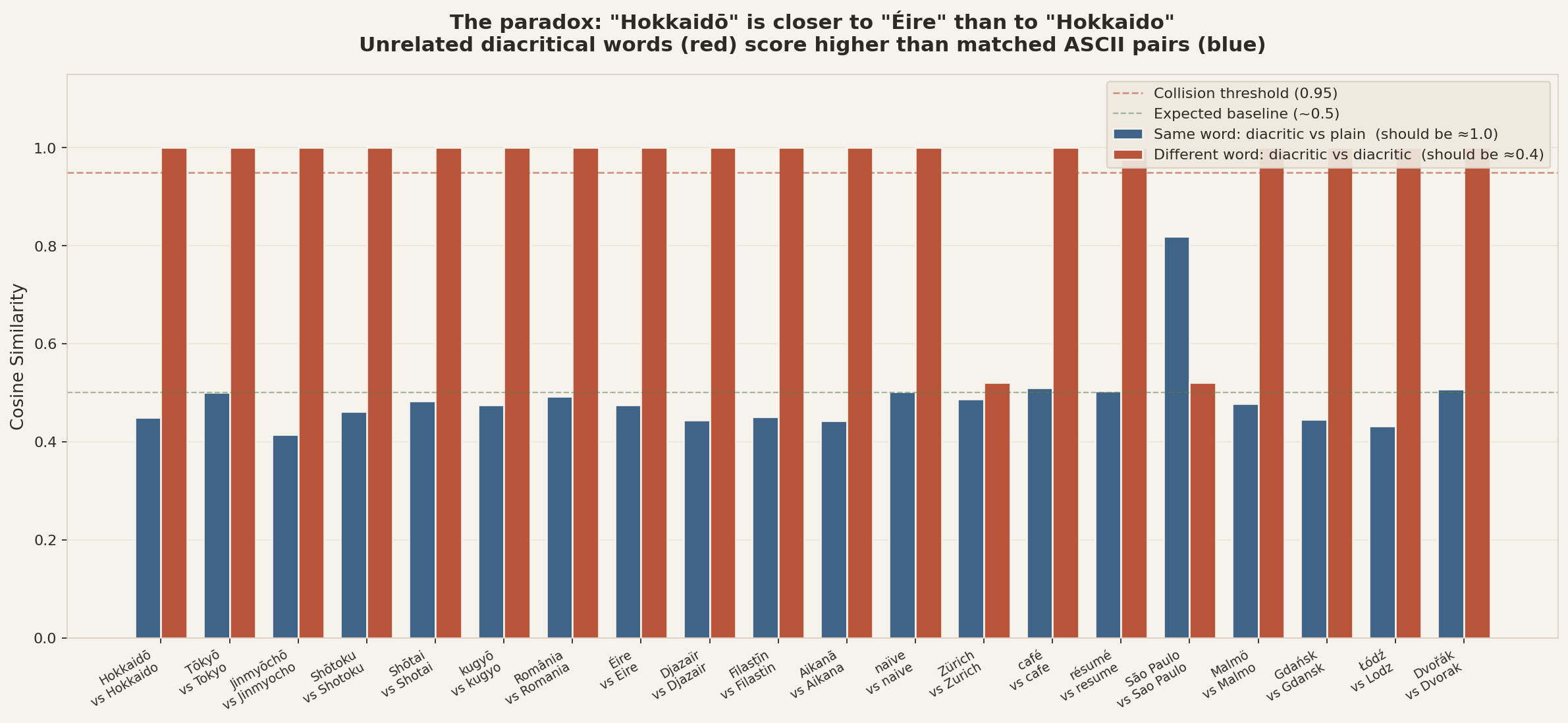
Result: “Hokkaidō” (a Japanese island) and “Éire” (Ireland in Irish) produce identical embeddings — cosine similarity 1.000 to six decimal places. Meanwhile “Hokkaidō” has cosine similarity only 0.51 to its own ASCII spelling “Hokkaido”. The diacritical version of a word is closer to a random other diacritical word than to itself.
But via the upstream HuggingFace tokenizer, the defect does not reproduce.
HF's BertTokenizer strip-accents preprocessing handles diacritics correctly.
The bug lives in the conversion pipeline from HuggingFace to gguf / Ollama, not in the
upstream mxbai weights. That makes it a defect class that affects every BERT-derived
embedding model deployed via Ollama, not just this one model.
Every number on this page is regenerated automatically. The pipeline is two scripts:
scripts/verify_tokenizer_divergence.py runs the upstream HuggingFace
tokenizer and the archived gguf via Ollama side-by-side and writes
verification/tokenizer_divergence.json. Then
scripts/generate_defect_page.py rebuilds the figures and this page
from that JSON. The “archived” gguf refers to
model/mxbai-embed-large-v1.gguf, shipped in this repo so the result
is reproducible even if the upstream mxbai weights are patched.
Every cell shows the cosine similarity between two words containing diacritical marks. In a working embedding model, unrelated words should have cosine around 0.3–0.5. Instead, nearly every pair is at 1.00. The one cell around ~0.5 ("São Paulo") has an internal space that resets WordPiece on its second, ASCII-only word.
Compare two cosines for each word in the 20-word sample: the word vs its own ASCII spelling (blue), and the word vs a different diacritical word (terracotta). A working model should put the blue bars near 1.0 and the terracotta bars near 0.5. The actual result is the exact inverse.
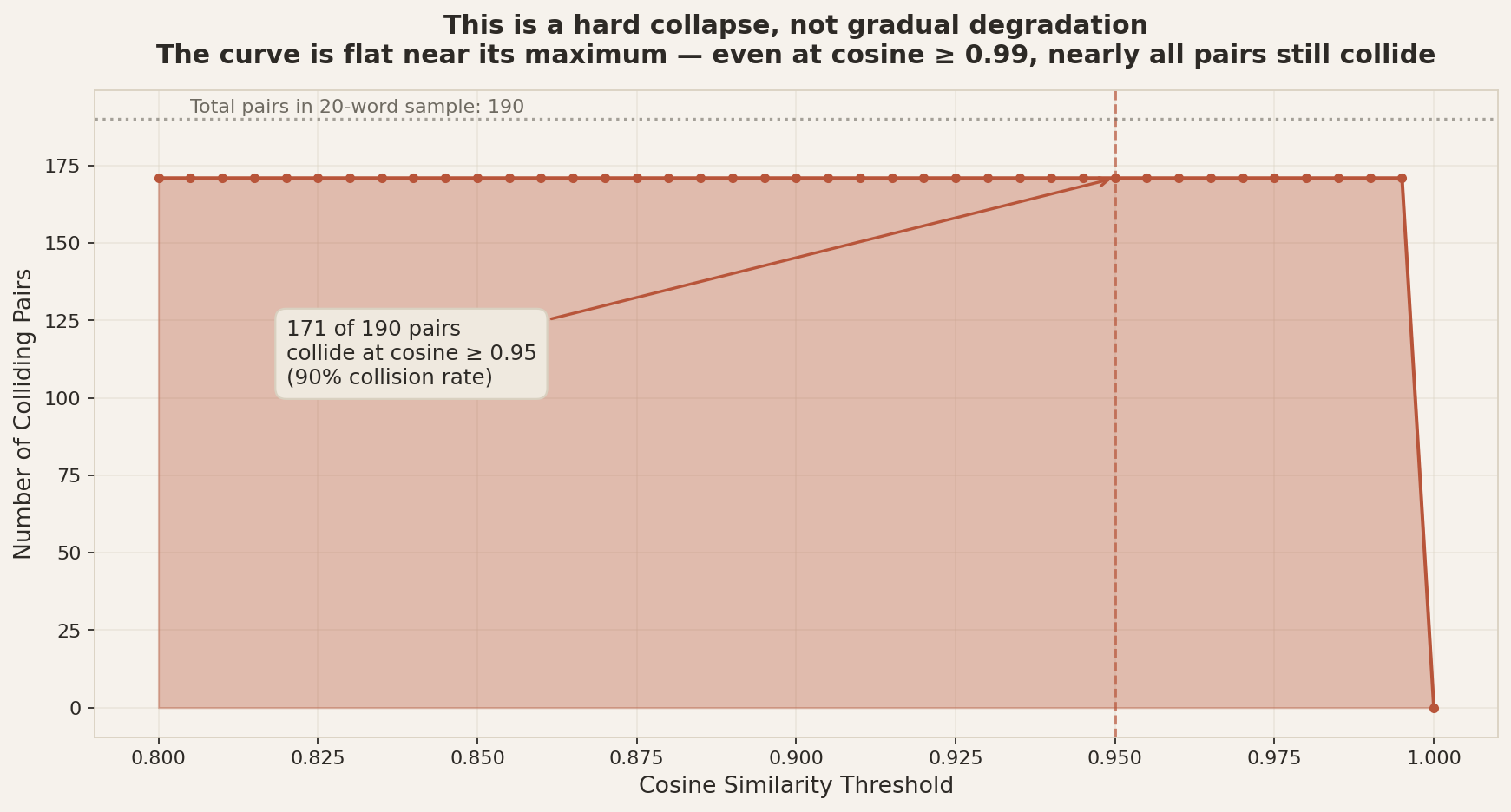
If the failure mode were soft blur — diacritical marks adding noise that gradually erodes similarity — the number of colliding pairs would drop smoothly as the threshold is raised. It doesn't. The curve is flat all the way up to 0.99.
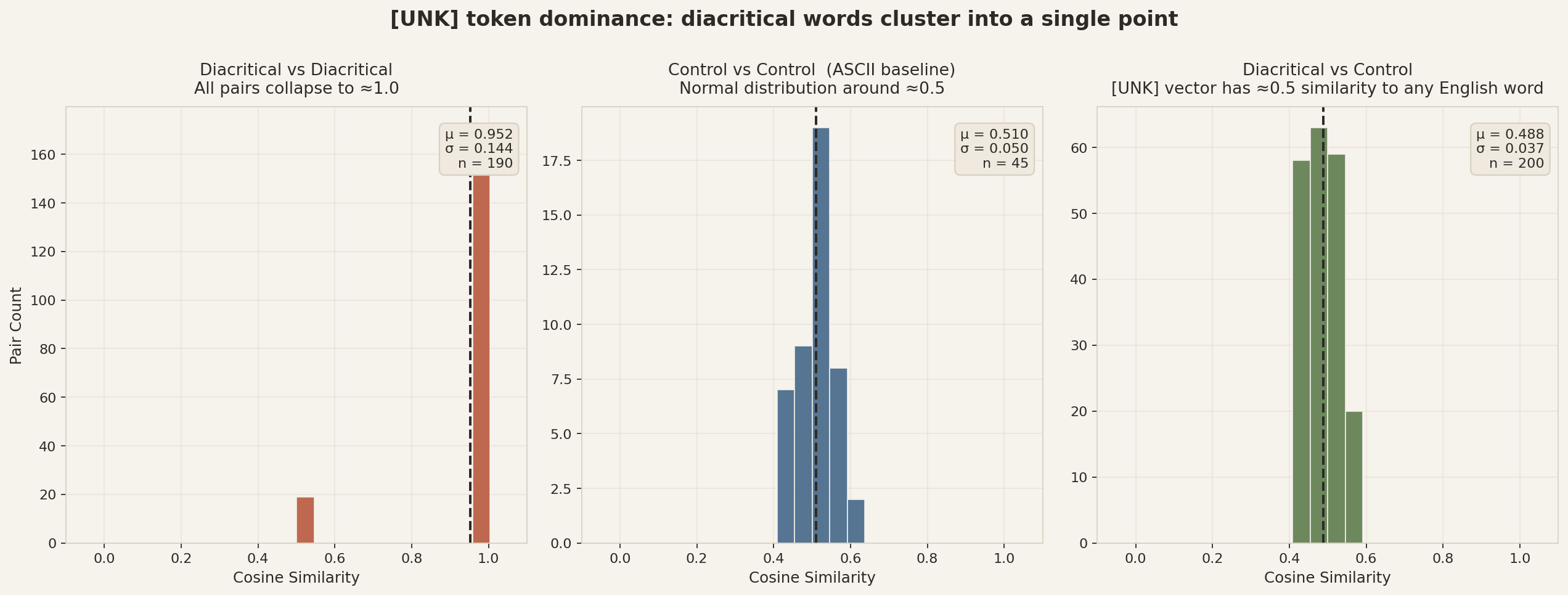
Three similarity distributions side by side. The diacritical-vs-diacritical panel (left) is a spike at 1.0, not a bell curve — compare to the control panel (middle), which shows what a healthy embedding space actually produces.
BertTokenizer strips accentsUpstream HuggingFace BertTokenizer strips accents for 9 of 10 test pairs — the diacritical form and the ASCII form produce identical token IDs. (do_lower_case=True, strip_accents=None which defaults to accent-stripping when lower-casing is on.) The one non-identical pair involves Ł, a distinct Latin letter rather than a decomposable combining diacritical, so NFD normalization leaves it alone.
| Diacritical | ASCII | HF tokens (diacritic) | HF tokens (ASCII) | |
|---|---|---|---|---|
| Hokkaidō | = | Hokkaido | hokkaido | hokkaido |
| Éire | = | Eire | e ##ire | e ##ire |
| Zürich | = | Zurich | zurich | zurich |
| café | = | cafe | cafe | cafe |
| Dvořák | = | Dvorak | d ##vor ##ak | d ##vor ##ak |
| naïve | = | naive | naive | naive |
| São Paulo | = | Sao Paulo | sao paulo | sao paulo |
| Malmö | = | Malmo | malmo | malmo |
| Gdańsk | = | Gdansk | gdansk | gdansk |
| Łódź | ≠ | Lodz | łodz | lo ##d ##z |
When the same mxbai weights are loaded through Ollama (from
model/mxbai-embed-large-v1.gguf, registered as
mxbai-archived via this repo's model/Modelfile),
diacritical characters are preserved all the way into the WordPiece step.
Since those characters are not in the WordPiece vocab and the gguf tokenizer has
no character-level fallback, the whole whitespace-delimited token becomes
[UNK]. For short inputs this single [UNK] dominates the
mean-pooled embedding, and every diacritical string ends up at the same point:
"Hokkaidō" → [CLS] [UNK] [SEP]
"Éire" → [CLS] [UNK] [SEP]
"Zürich" → [CLS] [UNK] [SEP]
"café" → [CLS] [UNK] [SEP]
"Dvořák" → [CLS] [UNK] [SEP]Empirically, on the archived gguf via Ollama, diacritical-vs-ASCII same-word cosine is 0.511 (should be ≈1.0 if the tokenizer is clean) and diacritical-vs-diacritical different-word cosine is 0.904 (should be ≈0.513, the ASCII control baseline).
The top cross-diacritic cosine similarities on the archived mxbai gguf via Ollama. A working model should score unrelated words around 0.3–0.5. These are the cosines actually produced on the reproducibly frozen weights:
| Diacritical word A | Diacritical word B | Cosine similarity |
|---|---|---|
| Hokkaidō | Éire | 1.0000 |
| Hokkaidō | Zürich | 1.0000 |
| Hokkaidō | café | 1.0000 |
| Hokkaidō | Dvořák | 1.0000 |
| Hokkaidō | naïve | 1.0000 |
| Hokkaidō | Malmö | 1.0000 |
| Hokkaidō | Gdańsk | 1.0000 |
| Hokkaidō | Łódź | 1.0000 |
The mechanism is not a WordPiece limitation. HF's BertTokenizer applies
BasicTokenizer's accent-stripping (via NFD normalization plus combining-mark
removal) before WordPiece sees the string. That preprocessing is wired in when
do_lower_case=True. The gguf conversion pipeline that produces the Ollama
model drops this preprocessing step: the gguf tokenizer sees raw Unicode diacritics,
has no way to match them to its WordPiece vocab, and emits [UNK].
Because the preprocessing step is a function of the BERT tokenizer config (not of any model-specific training), the same defect class is expected to affect every BERT-derived embedding model exported to gguf via the same conversion pipeline. The next section measures that.
The verification script runs the same diacritic-vs-ASCII probe against every BERT-family embedding model registered in local Ollama. Each row reports three mean cosine similarities:
A healthy model has S ≈ 1 and D ≈ C. A model with a diacritic attractor has D >> C. A model with an “[UNK] collapse” additionally has S ≈ C (the same word's ASCII form is no more similar than an unrelated word).
| Model (via Ollama) | S: diac↔ASCII same word | D: diac↔diac different words | C: ASCII control baseline | Severity | Failure mode |
|---|---|---|---|---|---|
mxbai-archived | 0.511 | 0.904 | 0.513 | 0.78 | Full collapse |
nomic-embed-text | 0.888 | 0.992 | 0.426 | 0.58 | Diacritic attractor |
all-minilm | 0.240 | 0.875 | 0.214 | 1.32 | Full collapse |
Every BERT-derived embedding model we tested via Ollama has a failure mode on
diacritical text. mxbai-archived and all-minilm exhibit the full [UNK]
collapse; nomic-embed-text has a softer but still-severe diacritic attractor (its
unrelated diacritic pairs cluster at cosine ~0.99, even though it recognizes
same-word ASCII equivalents). This is not a one-off bug in one model —
it's a systemic defect class at the deployment-tooling layer.
| Domain | Impact | Example |
|---|---|---|
| Multilingual NLP via Ollama | Critical | Any language with diacritics (French, German, Japanese romaji, Polish, Czech, Arabic transliteration…) |
| Knowledge graphs via Ollama | Critical | Wikidata entity labels with non-ASCII characters become indistinguishable |
| RAG / retrieval via Ollama | High | Documents about “Malmö” match queries about “Dvořák” |
| Semantic search via Ollama | High | Any product/person/place name with accented characters |
Upstream HF transformers |
Unaffected | HF's BertTokenizer strips accents in preprocessing — the bug lives below this layer |
| English-only ASCII workloads | Unaffected | Standard ASCII text works fine regardless of deployment layer |
Everything on this page regenerates from two scripts, using the frozen gguf shipped in this repository so the result is stable even if the upstream mxbai weights are patched:
# 1. Register the archived gguf in Ollama
cd model/
ollama create mxbai-archived -f Modelfile
cd ..
# 2. Run the verification script (writes verification/tokenizer_divergence.json)
pip install transformers # for the upstream HF probe
python scripts/verify_tokenizer_divergence.py
# 3. Regenerate figures and this page from the JSON artifact
python scripts/generate_defect_page.py
The older single-file demo (scripts/demo_collisions.py) still works and
is faster if you just want to see the defect — it embeds 25 pairs via Ollama
and writes collisions.csv. That script is the one reproduced daily by
GitHub Actions, and the CSV it produces is deterministic (the collisions do not
drift between runs), which is itself part of the result.
do_lower_case=True need their BasicTokenizer
preprocessing (NFD normalization + combining-mark strip) carried through
gguf conversion. Without this, WordPiece sees raw diacritics and emits
[UNK].nomic-embed-text on some versions, or SentencePiece-based
multilingual models) are less exposed, though our probe shows even
nomic-embed-text via Ollama has a softer diacritic attractor.This defect was discovered during the Latent Space Cartography project, which applies Vector Symbolic Architecture (VSA) analysis to frozen text embeddings. When probing Wikidata entity embeddings for relational structure, the collision pattern was unmistakable: 147,687 cross-entity pairs at cosine ≥ 0.95, all involving diacritical text. The full analysis is documented in our paper “Latent Space Cartography Applied to Wikidata: Relational Displacement Analysis Reveals a Silent Tokenizer Defect in mxbai-embed-large” (clawRxiv 2604.00648).